
DiffSeg — Unsupervised Zero-Shot Segmentation with Stable Diffusion
Unofficial PyTorch reimplementation of DiffSeg (CVPR 2024) — segment any image with zero labels, zero training, zero text prompts, using only the self-attention maps of a frozen Stable Diffusion UNet.
Overview
This project is an unofficial PyTorch reimplementation of DiffSeg, presented at CVPR 2024 by Tian et al. from Google and Georgia Tech. The original codebase was written in TensorFlow 2 + KerasCV — this port brings the full algorithm to the PyTorch / HuggingFace diffusers ecosystem, with a live interactive Gradio demo deployed on HuggingFace Spaces.
A full paper breakdown is coming soon on my blog and Medium. Here I focus on the implementation decisions and what makes this project technically interesting.
What Problem Does It Solve?
Most segmentation models need one of:
- Dense annotations (pixel-level labels — expensive, time-consuming)
- A text prompt (like SAM or CLIP-based methods)
- Domain-specific training (not generalisable)
DiffSeg needs none of these. It segments any image — photos, illustrations, medical scans, satellite imagery — using only a frozen pre-trained Stable Diffusion model and zero additional training.
The Core Idea
Stable Diffusion's UNet contains self-attention layers that have implicitly learned to group objects together during generative training. The key observation from the paper:
Pixels belonging to the same object attend to the same set of other pixels.
This means the self-attention maps are already a form of unsupervised segmentation — they just need to be extracted and organised.
Pipeline
The pipeline (shown in the diagram below) has three main stages:

1 · Attention Extraction
One single denoising step is run at a chosen timestep (typically 50–200).
During this forward pass, PyTorch forward hooks tap into every self-attention
layer of the UNet via a custom AttnProcessor, capturing 16 attention tensors
at 4 spatial resolutions: 64×64, 32×32, 16×16, 8×8.
class CapturingAttnProcessor:
def __call__(self, attn, hidden_states, encoder_hidden_states=None, ...):
q = attn.to_q(hidden_states)
k = attn.to_k(hidden_states)
# compute weights, capture them, return correct output
weights = softmax(q @ k.T / scale)
attn._captured_weights = weights.detach()
...The key implementation challenge here was avoiding the bug present in naive monkey-patching
approaches: computing Q/K twice causes shape mismatches like (32768×64) vs (512×512).
Using a proper AttnProcessor solves this cleanly.
2 · Attention Aggregation
All 16 maps are aggregated into a single 4D tensor Af ∈ R^(64×64×64×64) using the paper's exact upsampling strategy — not bilinear interpolation on both axes (a common mistake), but:
- Key axis (what a pixel attends to): bilinear upsample
- Query axis (which pixel is looking): tile/repeat
# Key axis — bilinear interpolate the probability distribution
attn_4d = attn.reshape(1, n, src_res, src_res)
key_up = F.interpolate(attn_4d, size=(64, 64), mode="bilinear")
# Query axis — tile each low-res position to its high-res patch
query_up = key_up_2d.repeat_interleave(scale, dim=0)
.repeat_interleave(scale, dim=1)This asymmetric treatment is critical — bilinearly interpolating the query axis creates false intermediate attention values that corrupt the segmentation boundaries.
3 · Iterative KL-Divergence Merging
Starting from an M×M grid of anchor points, attention maps are iteratively merged when their symmetric KL divergence falls below a threshold:
KL(pᵢ ‖ pⱼ) < threshold → merge into one group
This is the "slider" in the live demo. Lower threshold = more fine-grained segments. Higher threshold = fewer coarse regions. Unlike K-means, no cluster count is needed upfront.
After merging, Non-Maximum Suppression converts the proposal maps into a clean integer label map, upsampled back to original image resolution using nearest-neighbor interpolation.
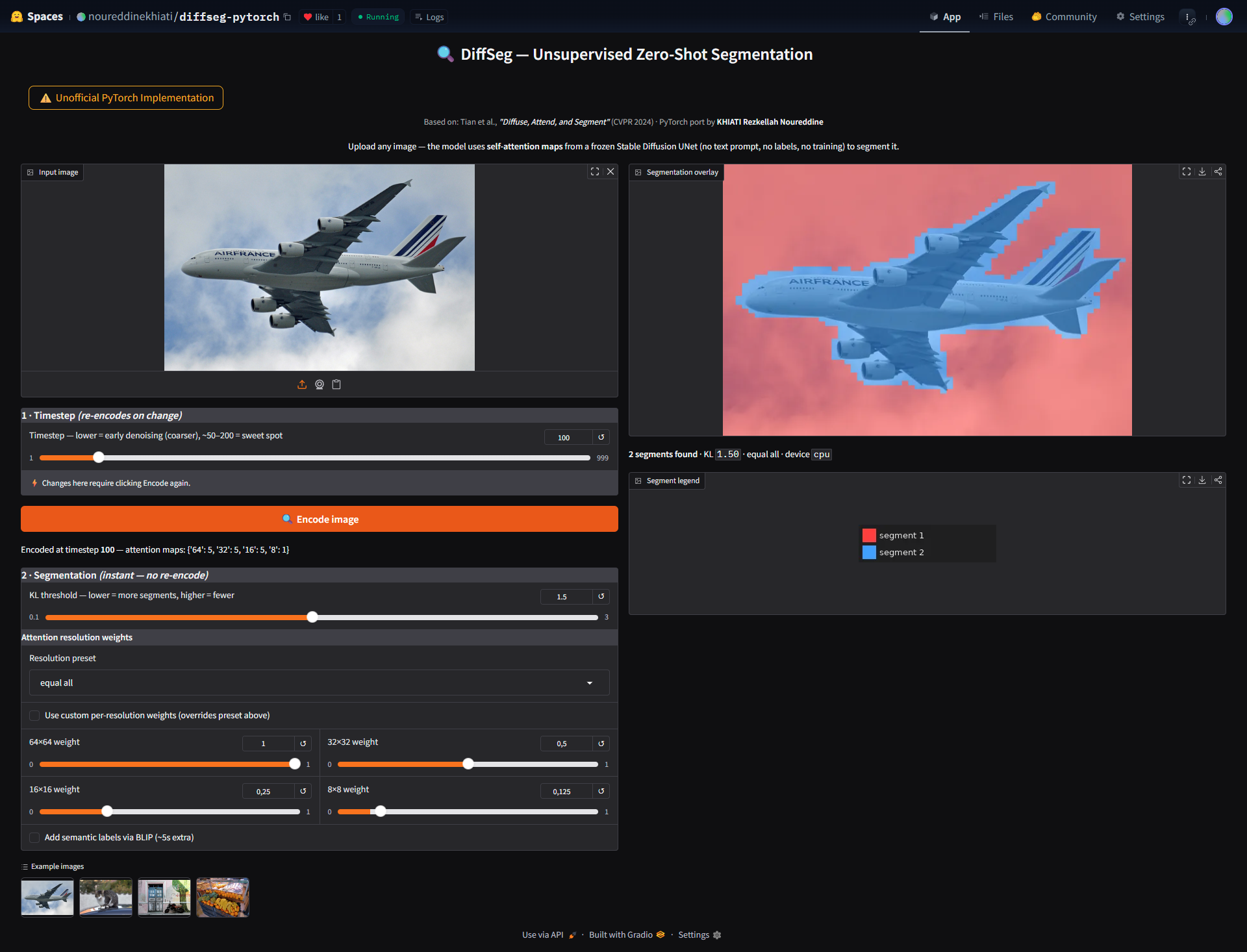
Live Demo Controls
The Gradio app exposes all algorithm parameters as interactive controls:
| Control | What it does | Requires re-encode? |
|---|---|---|
| Timestep | Which denoising step to extract attention from | ✅ Yes |
| KL threshold | Merge aggressiveness (more/fewer segments) | ❌ Instant |
| Resolution preset | Which attention resolutions to use (64²/32²/16²/8²) | ❌ Instant |
| w64 / w32 / w16 / w8 | Custom per-resolution weights | ❌ Instant |
| Semantic labels | BLIP caption + noun assignment per segment | ❌ Instant |
The key UX decision was caching the attention bundle after encode. The expensive SD forward pass (~3–5s on GPU) runs once. All slider interactions only re-run the cheap merging step (~0.1s).
A screenshot of the live demo (shown in the image below)
Implementation Differences from Original
| Original (TF/KerasCV) | This repo (PyTorch) | |
|---|---|---|
| Framework | TensorFlow 2.14 + KerasCV | PyTorch 2.x + diffusers |
| Attention extraction | KerasCV layer hooks | AttnProcessor (correct diffusers pattern) |
| Aggregation upsampling | Bilinear key + tile query | Same — paper-exact ✅ |
| Live demo | Jupyter notebook | Gradio app on HF Spaces |
| Parameters | Hardcoded | All interactive sliders |
Results
For this simple airplane image, using timestep=100, KL=1.2, resolution=64×64+32×32: the model cleanly separates the fuselage, wings, engines, tail, and sky — with no labels, no text, no fine-tuning.
The proportional aggregation strategy (higher weight to higher resolution maps) balances detail and coherence — matching the paper's Figure 4 ablation exactly.
What I Learned
- Diffusers
AttnProcessoris the correct way to intercept attention in modern diffusers — monkey-patchingforward()causes double-computation bugs that are hard to debug - Asymmetric upsampling (bilinear on key, tile on query) is a subtle but critical detail not obvious from the paper text alone — it took reading the actual formula carefully
- Caching architecture is essential for interactive ML demos — separating the expensive encode from the cheap segment step makes sliders feel instant
- Git LFS + HuggingFace binary file handling requires careful setup — the HuggingFace API
upload_folder()is more reliable than git push for Spaces deployment
Links
- 🤗 Live Demo: huggingface.co/spaces/noureddinekhiati/diffseg-pytorch
- 💻 GitHub: github.com/noureddinekhiati/diffseg-pytorch
- 📄 Paper: Tian et al., CVPR 2024 — arXiv:2308.12469
- ✍️ Paper breakdown: Coming soon on my blog
Citation
@inproceedings{tian2024diffuse,
title={Diffuse, Attend, and Segment: Unsupervised Zero-Shot Segmentation
using Stable Diffusion},
author={Tian, Junjiao and Aggarwal, Lavisha and Colaco, Andrea
and Kira, Zsolt and Gonzalez-Franco, Mar},
booktitle={CVPR},
year={2024}
}